概要
運用要件の変更で、コンテナの中のnginx.confを開発チームが触りたいとなったので、構成変更を行った際の備忘録です。
今までは、kubernetesのkostomizeで、configMapGeneratorを利用したconfigの生成を行なっていた為、別の方法でnginx.configを管理するように変更する方法を考える必要がありました。
要件は以下のようになります。
1. nginx.configだけを管理するGitリポジトリを作成
2. サイドカーとしてGitリポジトリを一定間隔でpullするコンテナを起動する
3. 更新があった場合、nginxプロセスをHUPシグナルを送信する
最初は公式のgit-syncを使い検証を行なっていました。
このイメージで上手く行けば良かったのですが、残念ながら
3. 更新があった場合、nginxプロセスをHUPシグナルを送信する
を行う為には各種パッケージを追加する必要があり、
それなら勉強の為に自前で同じ動きをさせてみよう!となりました。
app.py
アプリケーションの動きは、公式のgit-syncに合わせて、
GIT_SYNC_REPO ・・・ 対象リポジトリ
GIT_SYNC_BRANCH ・・・ 対象ブランチ
GIT_SYNC_DEST ・・・ 保存場所
を、環境変数から読み込むようにしました。
GIT_SYNC_DESTは、nginxコンテナからも読み込ませるので、emptyDirをvolumeとしてマウントしたPATHにします。
import os
import time
import git
import json
import subprocess
from datetime import datetime
def main():
while True:
dt = datetime.strftime(datetime.now(), '%Y/%m/%d %H:%M:%S')
log = {}
if os.path.exists(os.getenv("GIT_SYNC_DEST")):
repo = git.Repo(os.getenv("GIT_SYNC_DEST"))
repo.git.checkout(os.getenv("GIT_SYNC_BRANCH"))
git_result = repo.git.pull()
log["timestamp"] = dt
log["message"] = f'git pull from {os.getenv("GIT_SYNC_DEST")}'
print(json.dumps(log))
change_flg = 0
for log in git_result.splitlines():
if 'Updating' in log:
change_flg = 1
if change_flg == 1:
log = {}
dt = datetime.strftime(datetime.now(), '%Y/%m/%d %H:%M:%S')
cmd = 'pkill -HUP -f "nginx: master process"'
subprocess.call(cmd, shell=True)
log["timestamp"] = dt
log["message"] = 'exec HUP nginx master process'
print(json.dumps(log))
else:
git_result = git.Repo.clone_from(
os.getenv("GIT_SYNC_REPO"),
os.getenv("GIT_SYNC_DEST")
)
log["timestamp"] = dt
log["message"] = f'git clone {os.getenv("GIT_SYNC_REPO")} to {os.getenv("GIT_SYNC_DEST")}'
print(json.dumps(log))
time.sleep(60)
if __name__=="__main__":
main()
requirements
GitPython
Dockerfile
本来であればgitアクセスの際の利用するSSHの設定は、secretなどを使ってpodsに渡した方が良いですが、今回は割愛しています。
FROM ubuntu:latest
ENV TZ Asia/Tokyo
ENV DEBIAN_FRONTEND=noninteractive
USER root
RUN apt-get -y update && apt-get -y install tzdata procps python3 pip git\
&& apt-get clean && rm -rf /var/lib/apt/lists/*
ENV HOME=/tmp
WORKDIR /tmp
COPY .ssh /root/.ssh
COPY app /app
RUN pip3 install --upgrade pip
RUN pip3 install -r /app/requirements.txt
ENTRYPOINT [ "/bin/python3 /app/app.py" ]
deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
template:
spec:
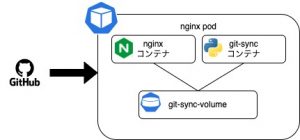
# サイドカーコンテナからnginxのプロセスを操作出来るようにする
shareProcessNamespace: true
containers:
# nginxコンテナ
- name: nginx
# 共有のからディレクトリをマウント
volumeMounts:
- name: git-sync-volume
mountPath: /tmp/git
env:
- name: NGINX_CONF
value: /tmp/git/nginx-config/conf.d
# nginxの起動前にconf.dディレクトリを/etc/nginx/conf.dに
# シンボリックリンクを貼ります。
# sleep を入れているのは、git pullでファイルの同期を待つ為に入れています
command: ["/bin/sh", "-c", "--"]
args: ["sleep 5 && ln -sf ${NGINX_CONF} /etc/nginx/conf.d && nginx -g \"daemon off;\""]
# git-sync コンテナ
- name: git-sync
image: git-sync:latest
imagePullPolicy: Always
volumeMounts:
- name: git-sync-volume
mountPath: /tmp/git
# 環境変数でリポジトリの情報を渡します
env:
- name: GIT_SYNC_REPO
value: "git@github.com:xxx/nginx-config.git"
- name: GIT_SYNC_BRANCH
value: master
- name: GIT_SYNC_DEST
value: "/tmp/git/nginx-config"
# git-syncコンテナから、nginxプロセスのPIDを取得する際に必要
securityContext:
capabilities:
add:
- SYS_PTRACE
restartPolicy: Always
volumes:
- name: git-sync-volume
emptyDir: {}
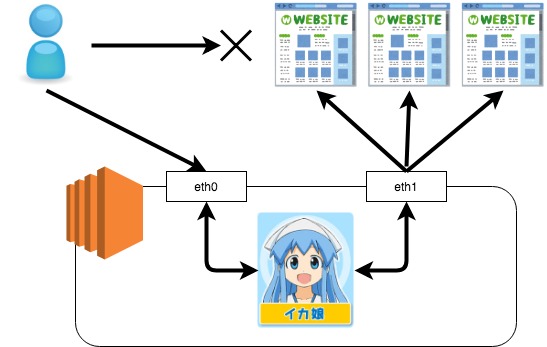
nginx-configリポジトリがmasterブランチが更新された場合、
git-syncコンテナが1分間隔でgit pullを行い
nginxコンテナの親プロセスにHUPを送信します。
これであれば、HUPの前にconfigtestを行い失敗したらSlackで通知を飛ばすとかも容易ですね。